Compare Models
- 07 Apr 2025
- 3 Minutes to read
- Print
- DarkLight
- PDF
Compare Models
- Updated on 07 Apr 2025
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
This article applies to these versions of LandingLens:
| LandingLens | LandingLens on Snowflake |
| ✓ | ✓ |
The Models page is a great way to get a high-level view of how different models performed on multiple datasets at once. However, if you'd like to see more details about how two specific models compare, use the Compare Models tool. The Compare Models tool is a great way to evaluate performance on multiple iterations of the model. It can help you identify if you need to improve your labels, datasets, and hyperparameters.
When you run the Compare Models tool, you set a baseline model and a candidate model. LandingLens then shows you if the candidate model performed better or worse across several metrics. You can even see a side-by-side comparison of how the baseline and candidate models performed on each image in the dataset.
 Compare Model Performance on an Evaluation Set
Compare Model Performance on an Evaluation Set
Note:
Comparisons are generated on-demand, and are not saved.
Run the Compare Models Tool
To compare two models:
- Open the project to the Models tab.
- Hover over the cell for one of the models you want to compare and click the Compare icon that appears. This model will be the baseline in the comparison. In other words, the second model will be compared as either better or worse than this model.
- Click the cell for the second model you want to compare. This model will be the candidate in the comparison. In other words, this model will be compared as either better or worse than the first model.Note:Want to switch the baseline and candidate models? Click the Switch icon.
- Click Compare.
.gif) Select the Models You Want to Compare
Select the Models You Want to Compare - The Compare Models window opens and shows the difference in performance between the two models.
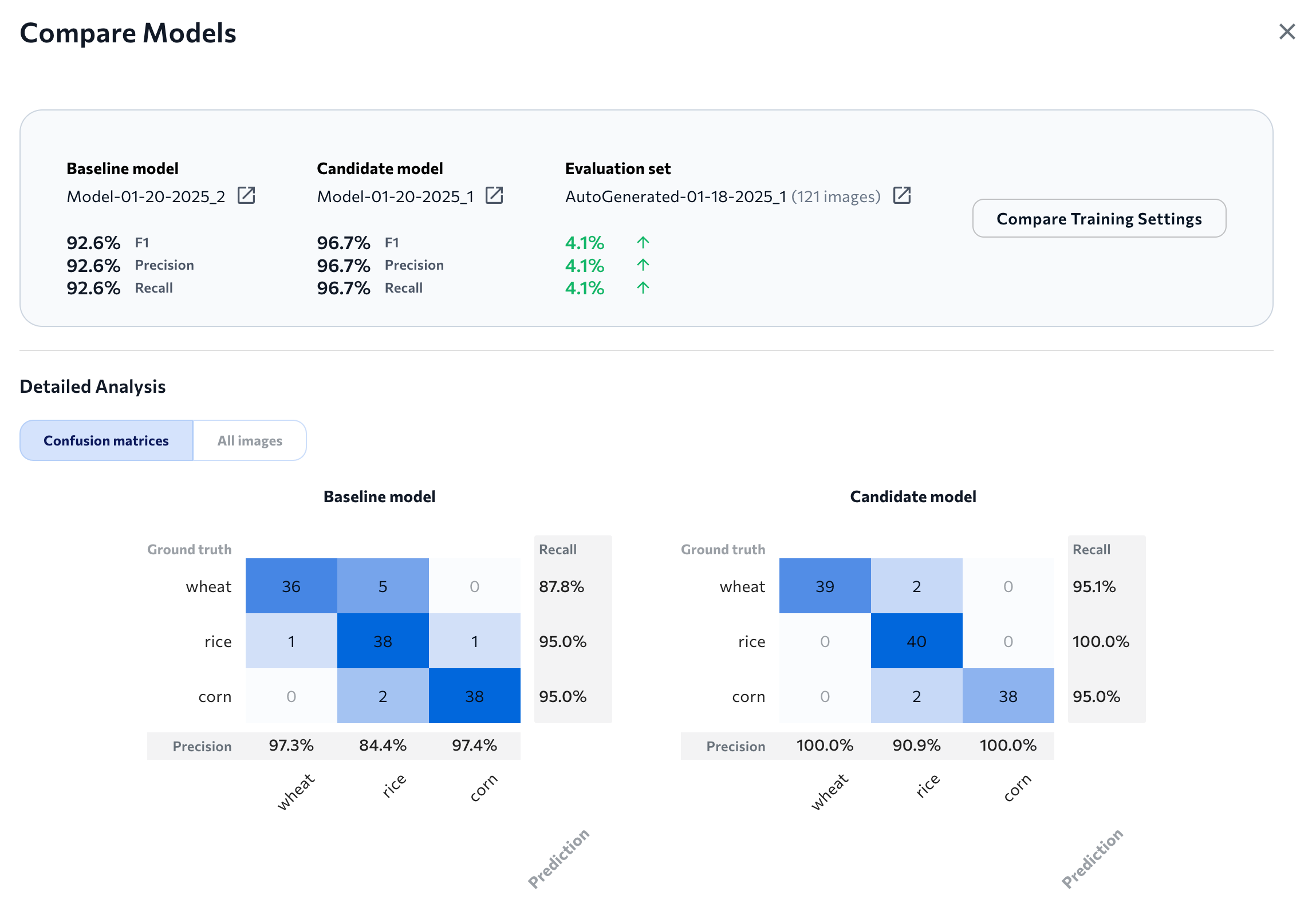 Model Comparison for the Evaluation Set
Model Comparison for the Evaluation Set
.gif)

Model Performance Scores
The top of the Compare Models window shows how each model performed on the evaluation set. It also shows the difference in score between the two models. For example, in the image below, The F1 score for the candidate model is 2.8% higher than the F1 score for the baseline model (92.3 - 89.5 = 2.8).
These performance scores are included:
- F1 (for Object Detection, Classification, and Anomaly Detection)
- IoU (for Segmentation)
- Precision
- Recall
.png) Compare Scores on the Evaluation Set
Compare Scores on the Evaluation Set
Compare Training Settings
To see the model training information for each model, click Compare Training Settings.
 Compare Training Settings
Compare Training Settings
This opens a table with a side-by-side comparison of the settings used to train each models. Differences in training settings are highlighted.
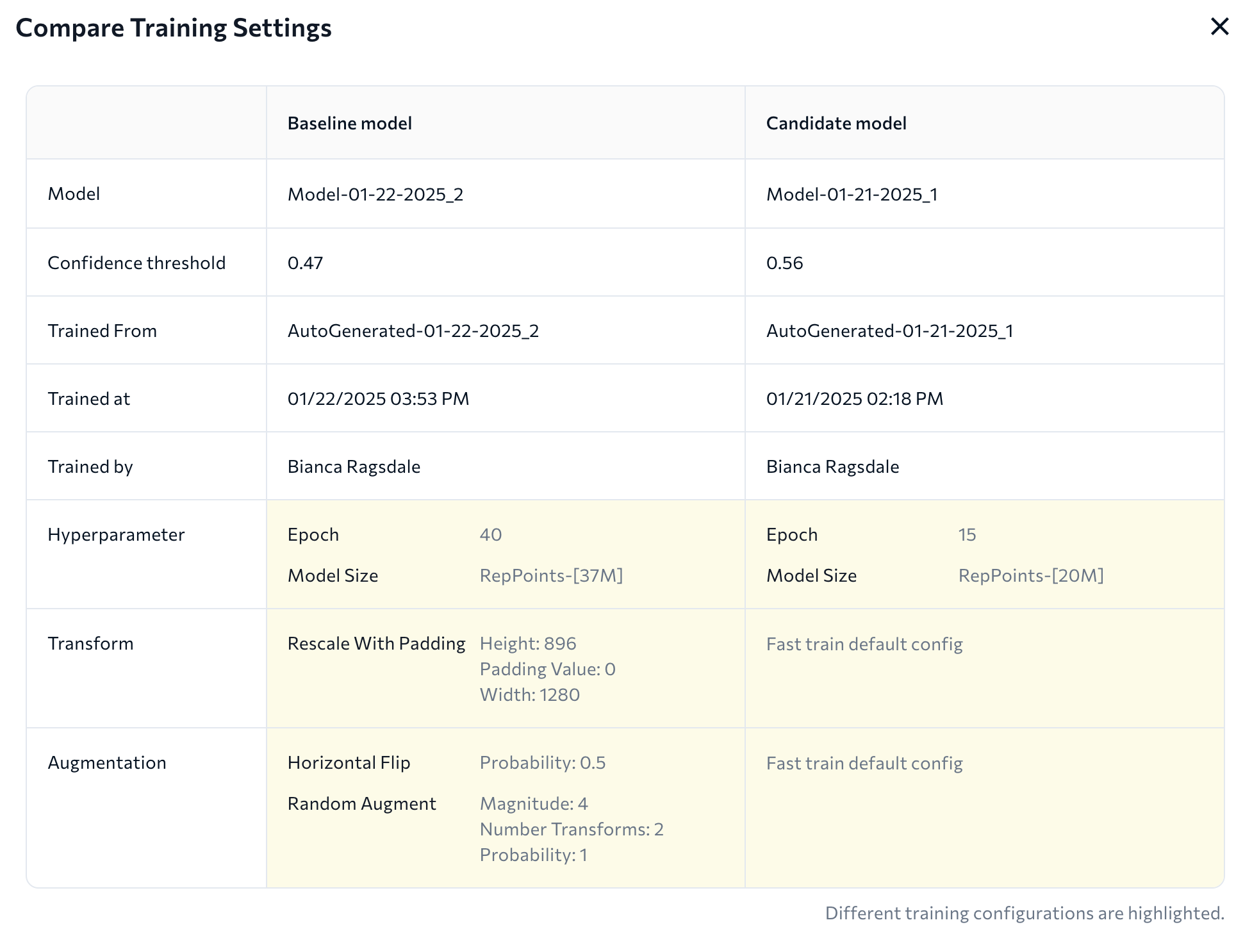 Side-by-Side Comparison of Model Training Settings
Side-by-Side Comparison of Model Training SettingsConfusion Matrices
The Compare Models window includes a confusion matrix for both the baseline and candidate model so that you can quickly compare how they performed on each class in the evaluation set.
Each confusion matrix counts ground truth labels versus model predictions. The y-axis represents each ground truth label. The x-axis represents each possible model prediction.
Each cell shows the count of images that correspond to particular ground truth class-predicted class pair. For example, in the image below, the baseline model correctly predicted the class "Dolphin" 15 times and misclassified it 7 times, whereas the candidate model correctly predicted it 19 times and misclassified it 3 times.
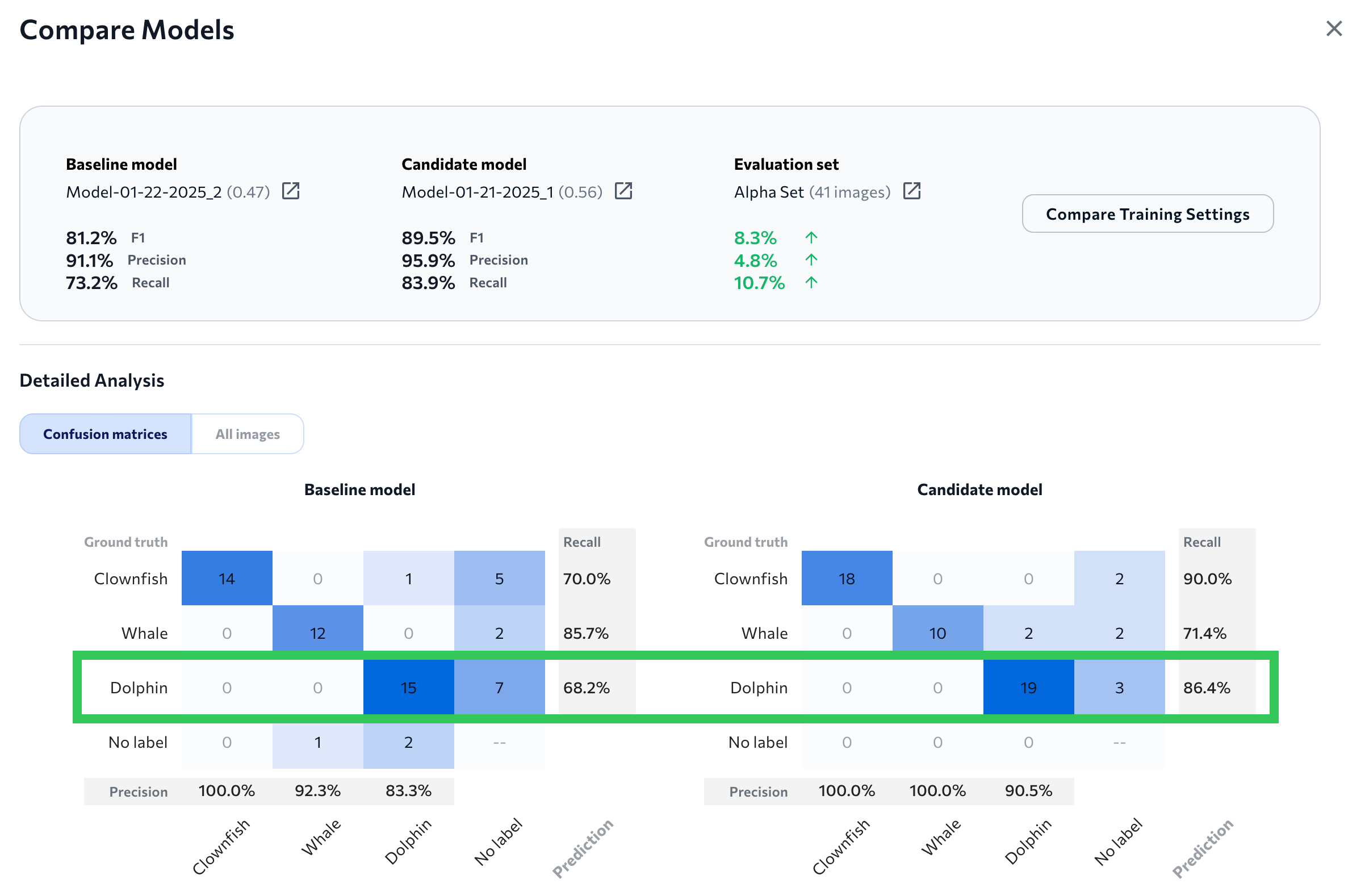 Compare the Confusion Matrices for Each Model
Compare the Confusion Matrices for Each ModelNote:
For detailed information about confusion matrices and their correspoding Precision and Recall scores, go to Performance Report.
Compare All Images
Click All Images to see a visual comparison of all images. This shows three versions of each image in the evaluation dataset:
- Ground truth: The original image with the ground truth (labels) that you added.
- Baseline model: The predictions of the candidate model.
- Candidate model: The predictions of the candidate model. LandingLens highlights an image if the candidate model performed better or worse than the baseline for that specific image.
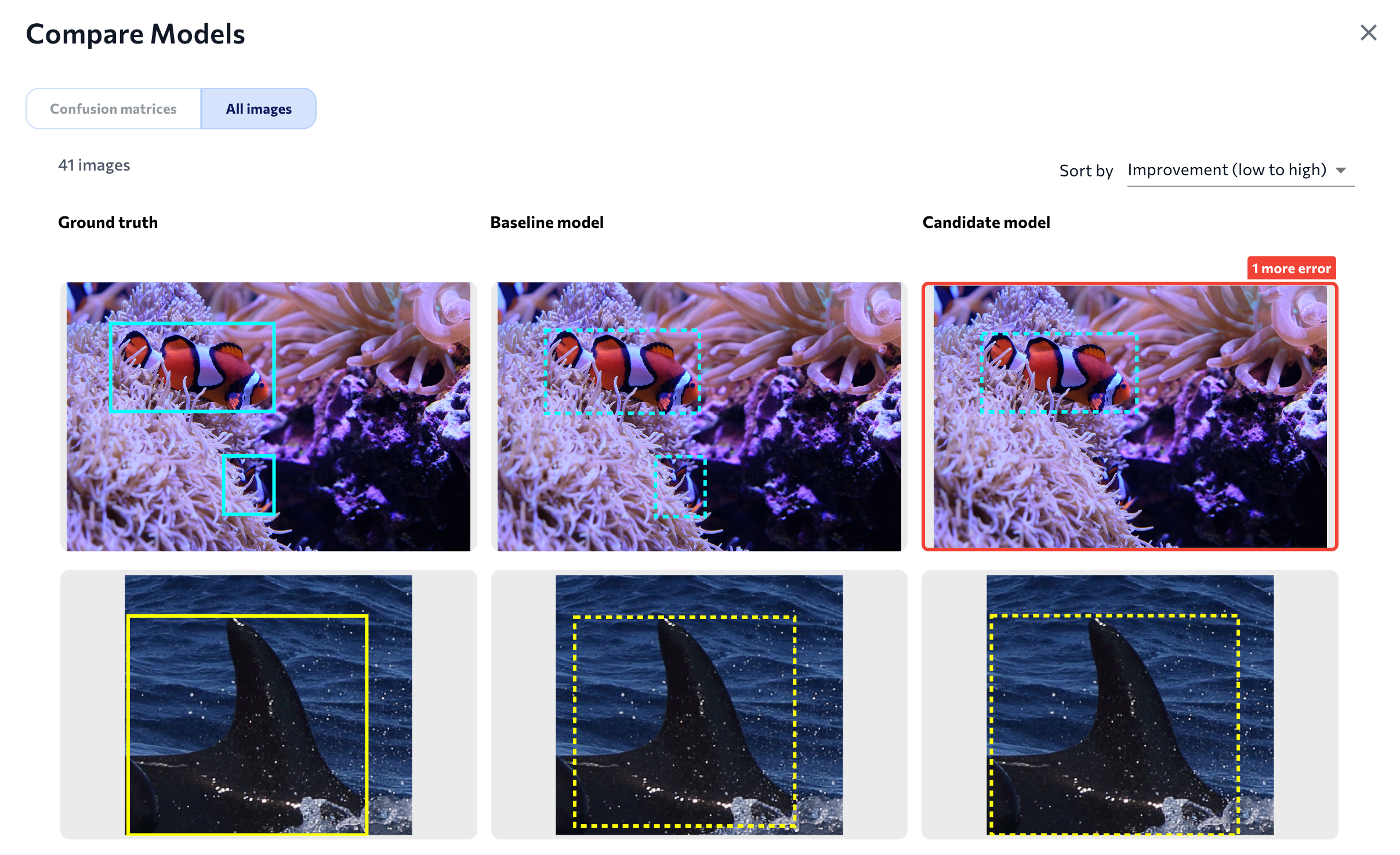 Compare All Images
Compare All ImagesClick a set of images to see more information about those images.
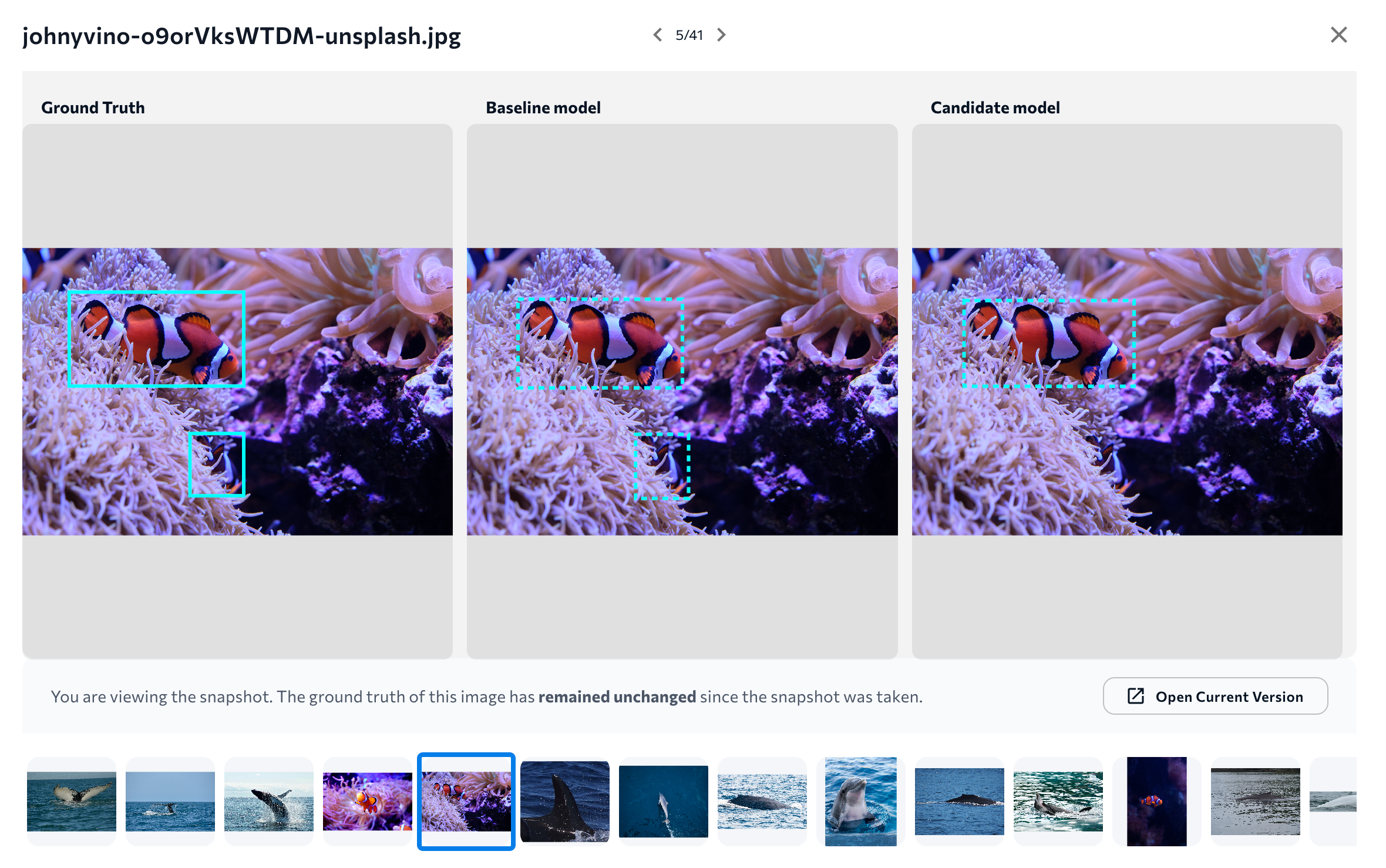 More Information About the Image
More Information About the ImageCompare All Images - Classification and Anomaly Detection
Because classes are assigned to an entire image in Classification and Anomaly Detection projects, it doesn't make sense to show the predictions as an overlay. Therefore, LandingLens shows the images and lists the ground truth and predictions next to the images.
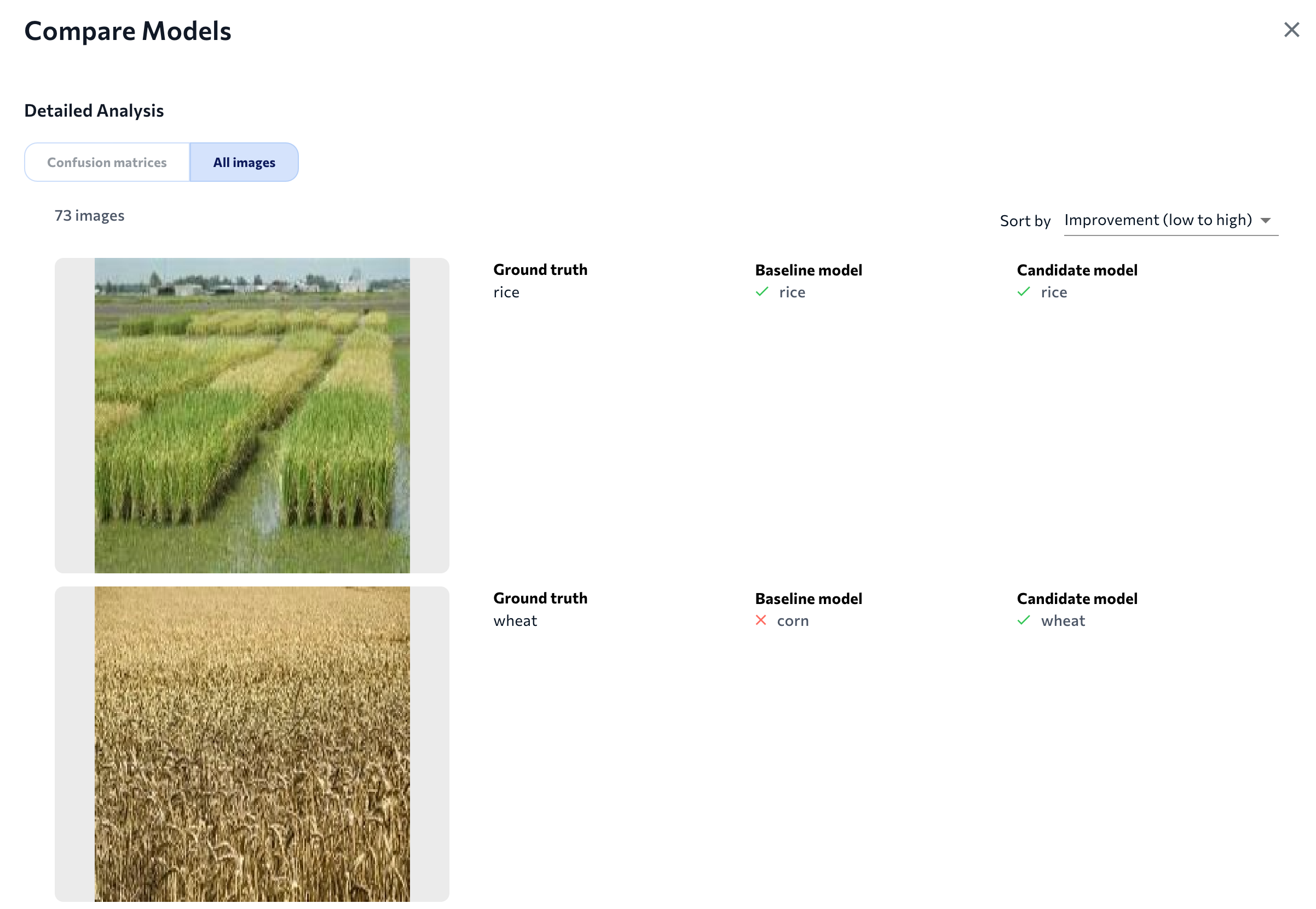 Compare Predictions on Images in a Classification Project
Compare Predictions on Images in a Classification ProjectWas this article helpful?