Cloud Inference (Run Live)
- 10 Jul 2024
- 2 Minutes to read
- Print
- DarkLight
- PDF
Cloud Inference (Run Live)
- Updated on 10 Jul 2024
- 2 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback
Cloud Inference
After you are happy with the results of your trained Model, you can run inference before you deploy your Model. Inference is the process of showing images to a Model that the Model has never seen before. This is done with the Run Live feature, the LandingLens-hosted cloud inference tool. This feature allows you to deploy a Model on a virtual device to test how it might behave in an actual deployment. You will be able to view the Model's:
- Inference time (how fast it predicts things)
- Accuracy (how well it predicts on a virtual device)
Note:
Cloud Inference is hosted in LandingLens. You must have access to LandingLens to use Cloud Inference.
How Cloud Inference Works
To run predictions on an image, you must create a Model Bundle. Then, upload new images (one at a time) onto the Deploy page. The platform scans these images and displays a Live Prediction. For example, let's say you have a Model trained to detect hardware in cereal. When you upload an image, the Model will predict whether the cereal has hardware in it.
 See a Live Prediction of an Uploaded Image
See a Live Prediction of an Uploaded Image
Using the Live Prediction before deployment is helpful because:
- You can see the accuracy of your Model.
- You can see where your Model might need to be improved.
Note:
Running Live Predictions is recommended, but not required, before Model deployment.
Run Live Predictions
After you have trained your Model, you can run Live Predictions on new images. Before you can run a Live Prediction, you must have created a Model Bundle.
Note:
The maximum image size is 4 MB.
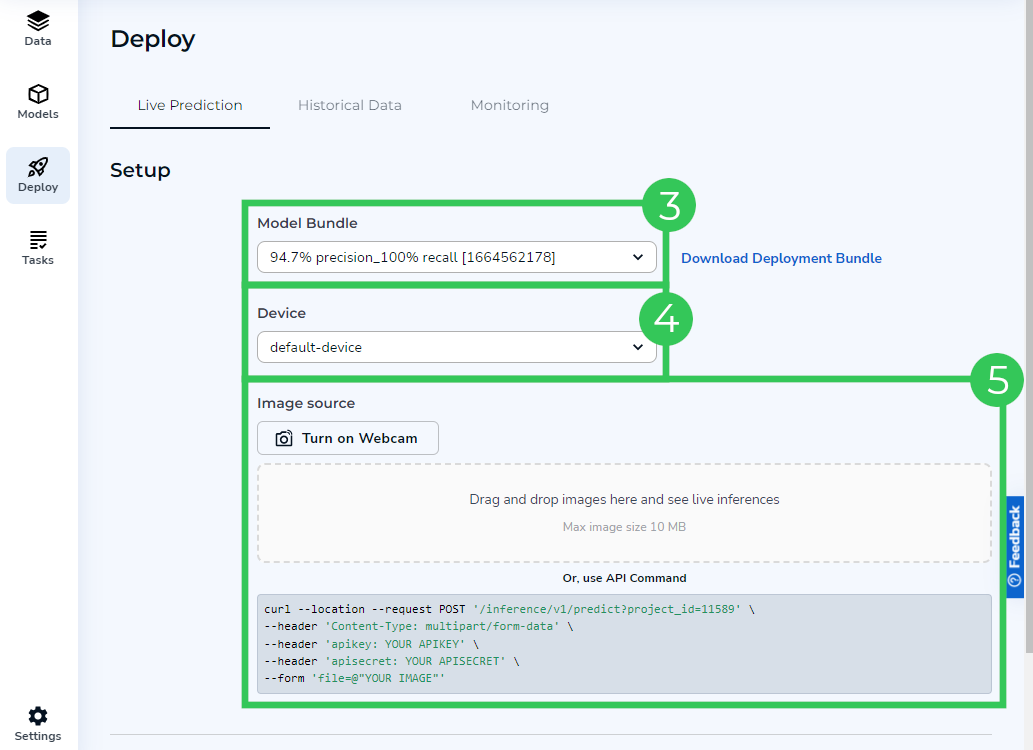
To run Live Predictions:
- Open the Project that has the Model Bundle you want to run Live Predictions on.
- Go to the Deploy page and stay on the Live Prediction tab.
- Select the Model Bundle you want to run Live Predictions on from the Model drop-down menu.
- Select a device from the Device drop-down menu.
- Upload an image by performing one of the following:
- Click Turn on Webcam to take an image and run inference on it.Note:If you have multiple webcams, Run Live will automatically choose the default camera setting for your browser. To change your default camera, check your browser's documentation.
- Drag an image to the Image Source box.
- Click the Image Source box to select an image.
- Call an API using the template in the API Command field.Note:For information on how to locate your API Key and API Secret, go here.
 Upload an Image to View Its Live Prediction
Upload an Image to View Its Live Prediction
- Click Turn on Webcam to take an image and run inference on it.
- LandingLens displays its Live Prediction of the image in the Predictions section. The Predicted Image is automatically saved to the Historical Data tab. This allows you to reference your Predicted Images later.
.png) Live Prediction Results
Live Prediction Results

.png)
Devices
Run Live allows you to deploy a Model on a virtual device to run inference. LandingLens is compatible with two types of devices: Static and Dynamic.
A Static device is for users on the legacy "classic" workflow and is only available for specific customers. If you want to use a Static device, reach out to your Landing AI contact, and we will help you set up the Static device.
A Dynamic device scales automatically as the user increases the number of images sent to run inference. It is for newer Projects created in the quick Project workflow. LandingLens automatically comes with a default Dynamic device for you to use. You can create a new one; however, it is not necessary.
 Dynamic and Static Devices
Dynamic and Static DevicesWas this article helpful?